# load packages
library(tidyverse)
library(tidymodels)
library(patchwork)
library(knitr)
library(kableExtra)
# set default theme and larger font size for ggplot2
ggplot2::theme_set(ggplot2::theme_bw(base_size = 20))Cross validation
Announcements
Lab 05 due TODAY at 11:59pm
HW 03 due Tuesday, March 17 at 11:59pm
Statistics experience due April 15
Please provide mid-semester feedback by Friday: https://duke.qualtrics.com/jfe/form/SV_3lvkRQbz7PMuJVA
Exam 02 date proposed date change
In-class: Thursday, April 9
Take-home: Thursday, April 9 - Saturday, April 11
Please email me by tomorrow if you have any concerns
Topics
- Training and testing sets
- Cross validation
Computational setup
Data: Restaurant tips
Which variables help us predict the amount customers tip at a restaurant? To answer this question, we will use data collected in 2011 by a student at St. Olaf who worked at a local restaurant.
# A tibble: 169 × 4
Tip Party Meal Age
<dbl> <dbl> <fct> <fct>
1 2.99 1 Dinner Yadult
2 2 1 Dinner Yadult
3 5 1 Dinner SenCit
4 4 3 Dinner Middle
5 10.3 2 Dinner SenCit
6 4.85 2 Dinner Middle
7 5 4 Dinner Yadult
8 4 3 Dinner Middle
9 5 2 Dinner Middle
10 1.58 1 Dinner SenCit
# ℹ 159 more rowsVariables
Predictors:
Party: Number of people in the partyMeal: Time of day (Lunch, Dinner, Late Night)Age: Age category of person paying the bill (Yadult, Middle, SenCit)Payment: Payment type (Cash, Credit, Credit/CashTip)
Response vs. predictors
Training vs. testing sets
The training set (i.e., the data used to fit the model) does not have the capacity to be a good arbiter of performance.
It is not an independent piece of information; predicting the training set can only reflect what the model already knows.
Suppose you give a class a test, then give them the answers, then provide the same test. The student scores on the second test do not accurately reflect what they know about the subject; these scores would probably be higher than their results on the first test.
We can reserve some data for a testing set that can be used to evaluate the model performance
Training and testing sets
Create training and testing sets using functions from the resample R package (part of tidymodels)
Step 1: Create an initial split:
set.seed(210)
tips_split <- initial_split(tips, prop = 0.75) #prop = 3/4 by defaultStep 2: Save training data
tips_train <- training(tips_split)
dim(tips_train)[1] 126 13Step 3: Save testing data
tips_test <- testing(tips_split)
dim(tips_test)[1] 43 13Application exercise
Cross validation
Spending our data
- We have already established that the idea of data spending where the test set was recommended for obtaining an unbiased estimate of performance.
- However, we usually need to understand the effectiveness of the model before using the test set.
- Typically we can’t decide on which final model to take to the test set without making model assessments.
- Remedy: Resampling to make model assessments on training data in a way that can generalize to new data.
Resampling for model assessment
Resampling is only conducted on the training set. The test set is not involved. For each iteration of resampling, the data are partitioned into two subsamples:
- The model is fit with the analysis set. Model fit statistics such as Adj. \(R^2\) and \(R^2\) are computed based on this model fit.
- The model is evaluated with the assessment set.
Resampling for model assessment

Image source: Kuhn and Silge. Tidy modeling with R.
Analysis and assessment sets
- Analysis set is analogous to training set.
- Assessment set is analogous to test set.
- The terms analysis and assessment avoids confusion with initial split of the data.
- These data sets are mutually exclusive.
Cross validation
More specifically, v-fold cross validation – commonly used resampling technique:
- Randomly split your training data into v partitions
- Use v-1 partitions for analysis, and the remaining 1 partition for analysis (model fit + model fit statistics)
- Repeat v times, updating which partition is used for assessment each time
. . .
Let’s give an example where v = 3…
To get started…
Split data into training and test sets
set.seed(210)
tips_split <- initial_split(tips, prop = 0.75)
tips_train <- training(tips_split)
tips_test <- testing(tips_split)To get started…
Specify model
tips_spec <- linear_reg(). . .
tips_specLinear Regression Model Specification (regression)
Computational engine: lm To get started…
Create workflow
tips_wflow1 <- workflow() |>
add_model(tips_spec) |>
add_formula(Tip ~ Age + Party). . .
tips_wflow1══ Workflow ════════════════════════════════════════════════════════════════════
Preprocessor: Formula
Model: linear_reg()
── Preprocessor ────────────────────────────────────────────────────────────────
Tip ~ Age + Party
── Model ───────────────────────────────────────────────────────────────────────
Linear Regression Model Specification (regression)
Computational engine: lm Cross validation, step 1
Randomly split your training data into 3 partitions:

Tips: Split training data
folds <- vfold_cv(tips_train, v = 3)
folds# 3-fold cross-validation
# A tibble: 3 × 2
splits id
<list> <chr>
1 <split [84/42]> Fold1
2 <split [84/42]> Fold2
3 <split [84/42]> Fold3Cross validation, steps 2 and 3
- Use v-1 partitions for analysis, and the remaining 1 partition for assessment
- Repeat v times, updating which partition is used for assessment each time

Cross validation: Tips data
There are 126 observations in the training data. How many observations are in a single assessment set?
Tips: Fit resamples
tips_fit_rs1 <- tips_wflow1 |>
fit_resamples(resamples = folds)
tips_fit_rs1# Resampling results
# 3-fold cross-validation
# A tibble: 3 × 4
splits id .metrics .notes
<list> <chr> <list> <list>
1 <split [84/42]> Fold1 <tibble [2 × 4]> <tibble [0 × 4]>
2 <split [84/42]> Fold2 <tibble [2 × 4]> <tibble [0 × 4]>
3 <split [84/42]> Fold3 <tibble [2 × 4]> <tibble [0 × 4]>Cross validation, now what?
- We’ve fit a bunch of models
- Now it’s time to use them to collect metrics (e.g., RMSE, \(R^2\) ) on each model and use them to evaluate model fit and how it varies across folds
Collect metrics from CV
# Produces summary across all CV
collect_metrics(tips_fit_rs1)# A tibble: 2 × 6
.metric .estimator mean n std_err .config
<chr> <chr> <dbl> <int> <dbl> <chr>
1 rmse standard 2.14 3 0.195 pre0_mod0_post0
2 rsq standard 0.623 3 0.0470 pre0_mod0_post0Note: These are calculated using the assessment data
Deeper look into results
cv_metrics1 <- collect_metrics(tips_fit_rs1, summarize = FALSE)
cv_metrics1# A tibble: 6 × 5
id .metric .estimator .estimate .config
<chr> <chr> <chr> <dbl> <chr>
1 Fold1 rmse standard 1.92 pre0_mod0_post0
2 Fold1 rsq standard 0.713 pre0_mod0_post0
3 Fold2 rmse standard 2.52 pre0_mod0_post0
4 Fold2 rsq standard 0.554 pre0_mod0_post0
5 Fold3 rmse standard 1.97 pre0_mod0_post0
6 Fold3 rsq standard 0.603 pre0_mod0_post0Better presentation of results
cv_metrics1 |>
mutate(.estimate = round(.estimate, 3)) |>
pivot_wider(id_cols = id, names_from = .metric, values_from = .estimate) |>
kable(col.names = c("Fold", "RMSE", "R-sq"))| Fold | RMSE | R-sq |
|---|---|---|
| Fold1 | 1.915 | 0.713 |
| Fold2 | 2.525 | 0.554 |
| Fold3 | 1.967 | 0.603 |
Cross validation in practice
To illustrate how CV works, we used
v = 3:- Analysis sets are 2/3 of the training set
- Each assessment set is a distinct 1/3
- The final resampling estimate of performance averages each of the 3 replicates
This was useful for illustrative purposes, but
vis often 5 or 10; we generally prefer 10-fold cross-validation as a default
Example model selection workflow
Exploratory data analysis
Using training data…
Fit and evaluate candidate models using cross validation
Select the best fit model
Check model conditions and diagnostics
Repeat as needed until you’ve landed on final model
Evaluate the final model performance using the test set
Tip
See Section 10.5.2 for more detailed workflow
Data analysis workflow
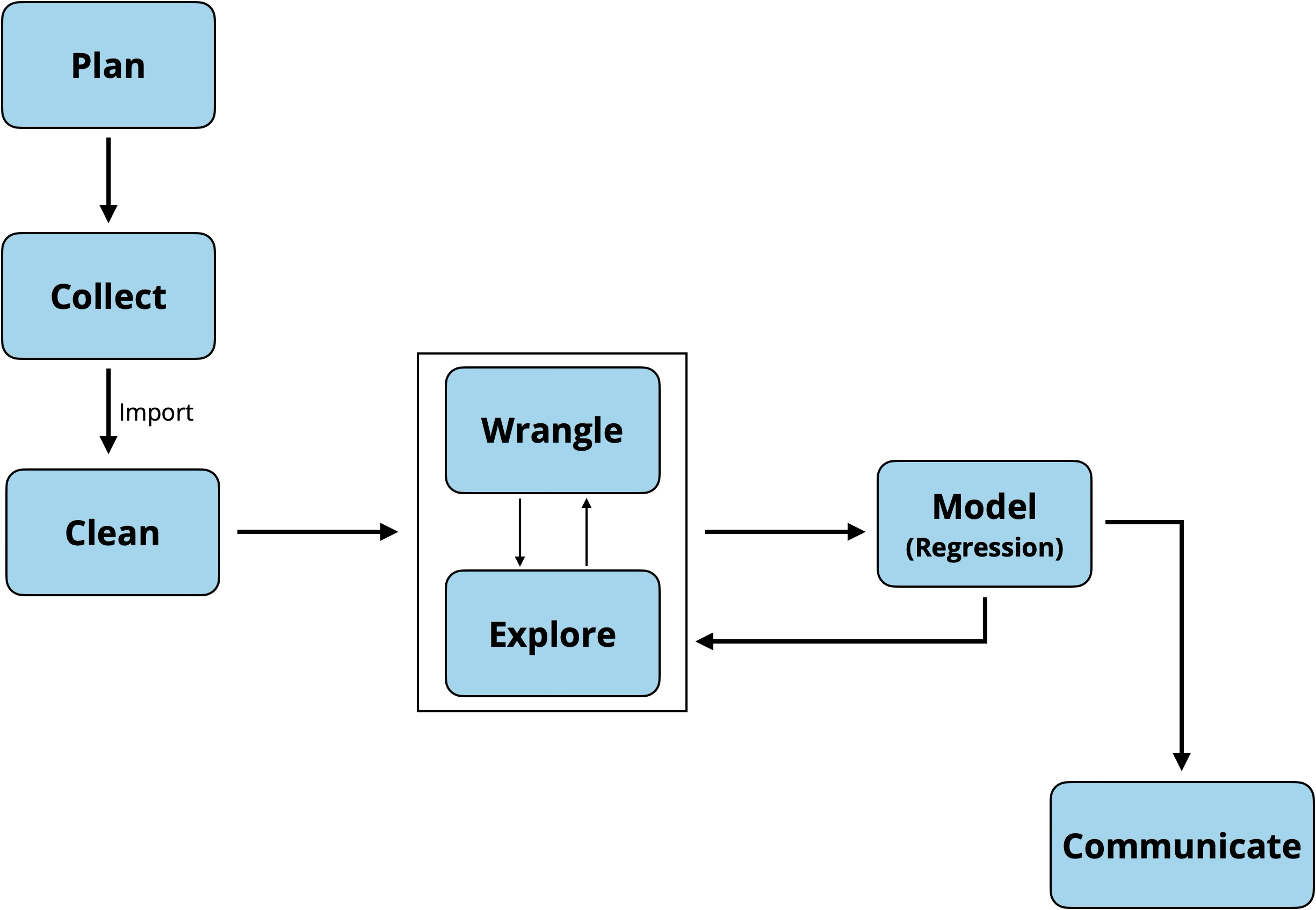
Recap
- Training and testing sets
- Cross validation
Next class
☀️ Have a good spring break ☀️