Logistic regression
Inference
Mar 24, 2026
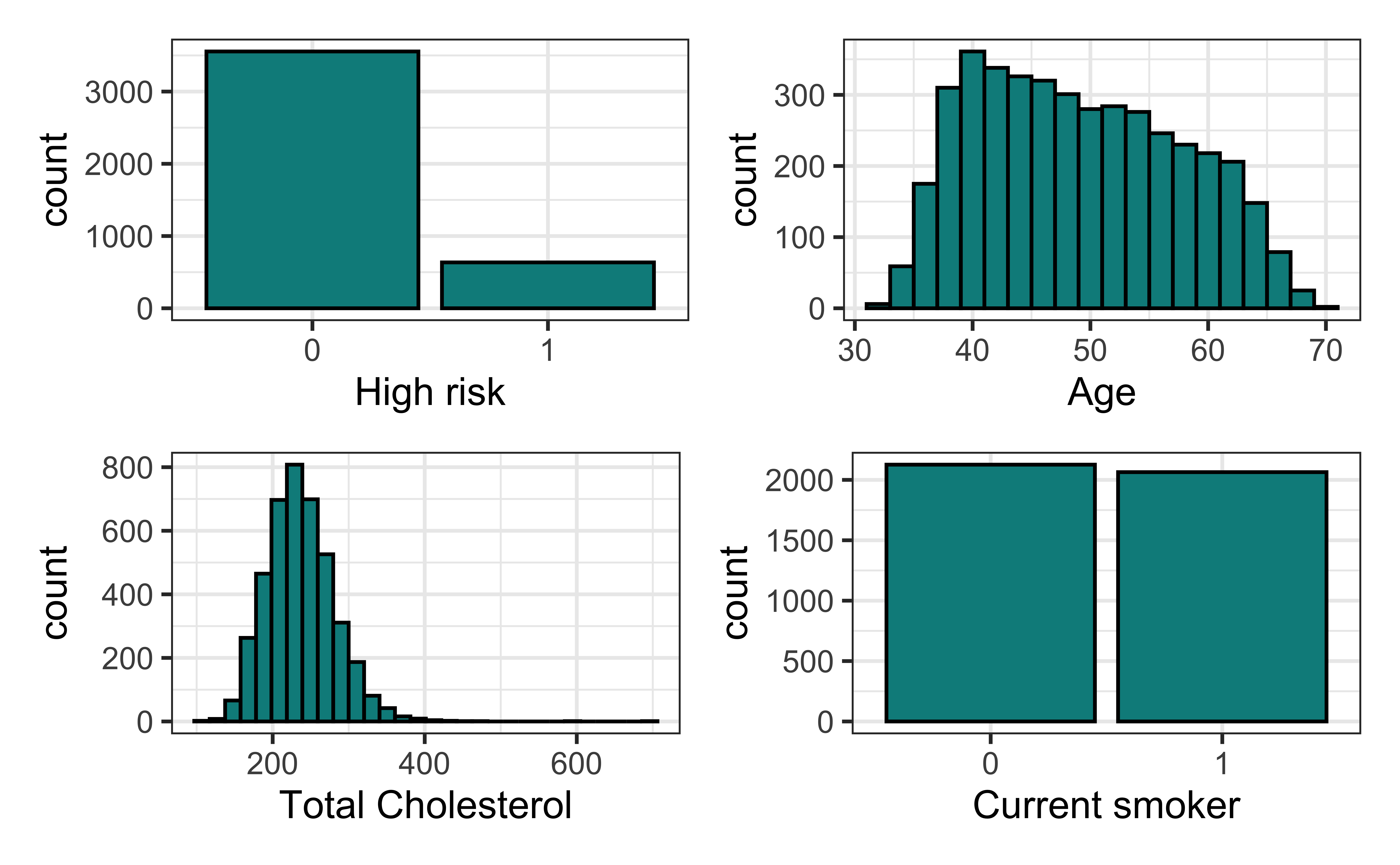
Univariate EDA
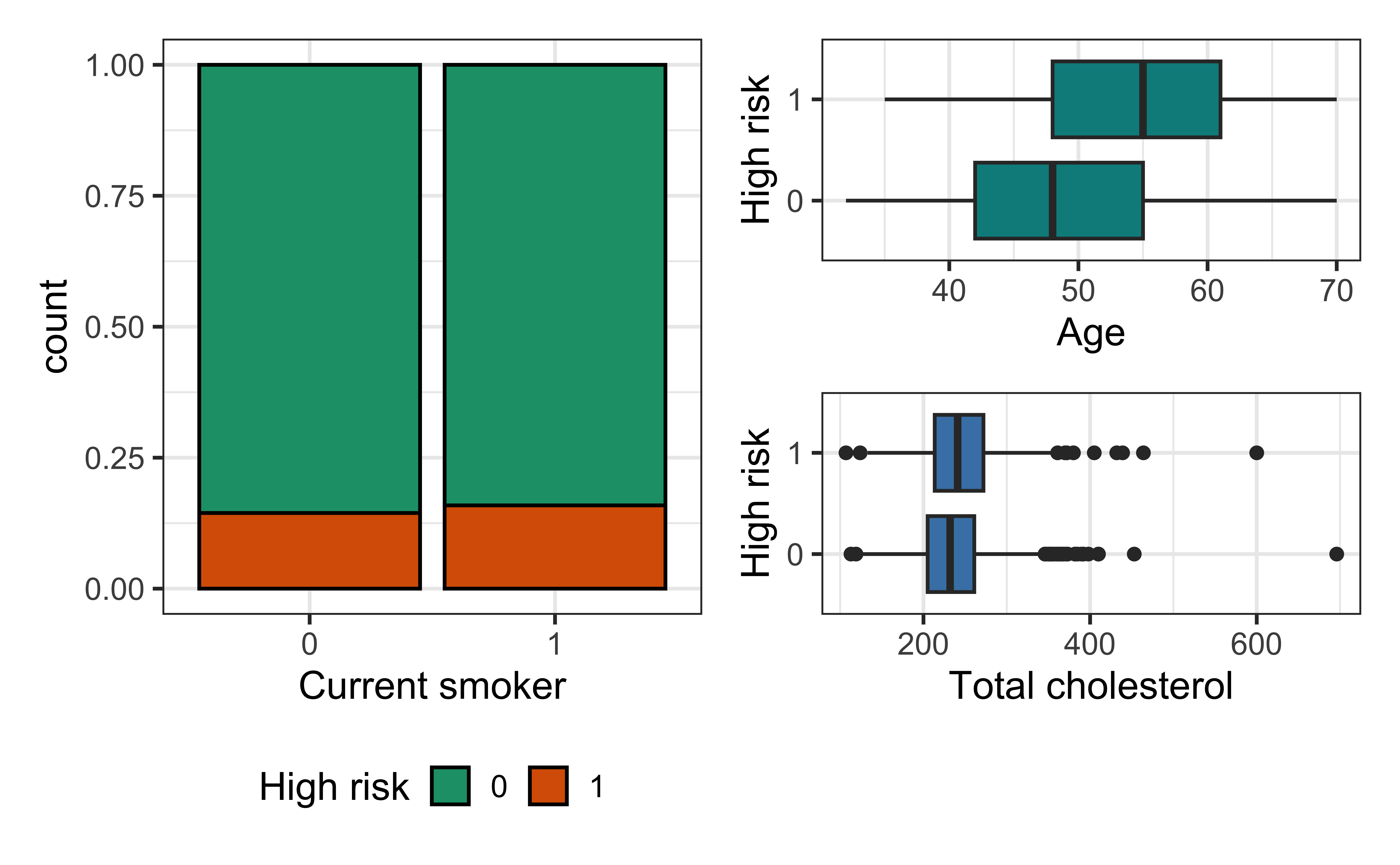
Bivariate EDA
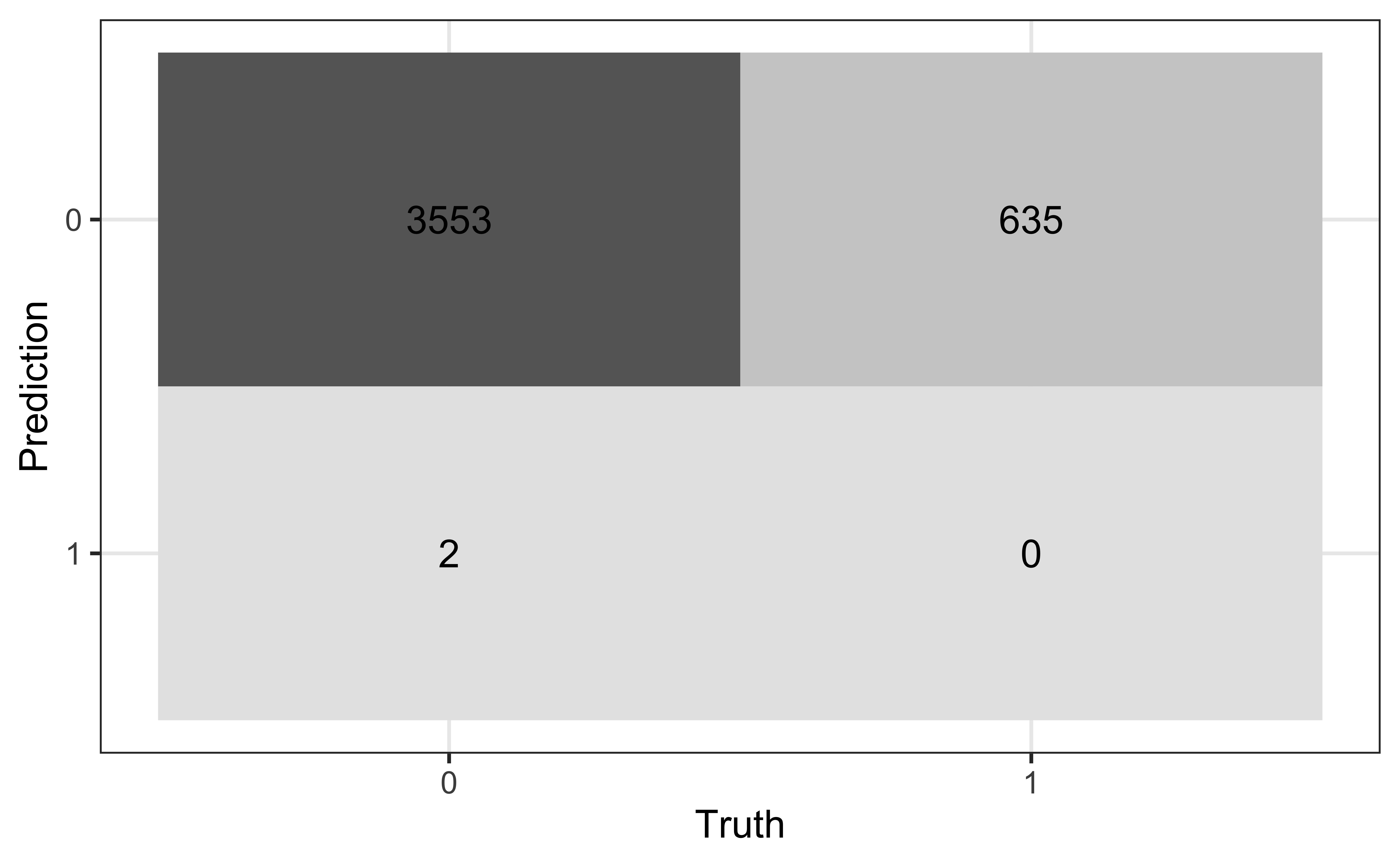
Confusion matrix
A confusion matrix is a \(2 \times 2\) table that compares the predicted and actual classes for a given threshold. We can produce this matrix using the conf_mat() function in the yardstick package (part of tidymodels).
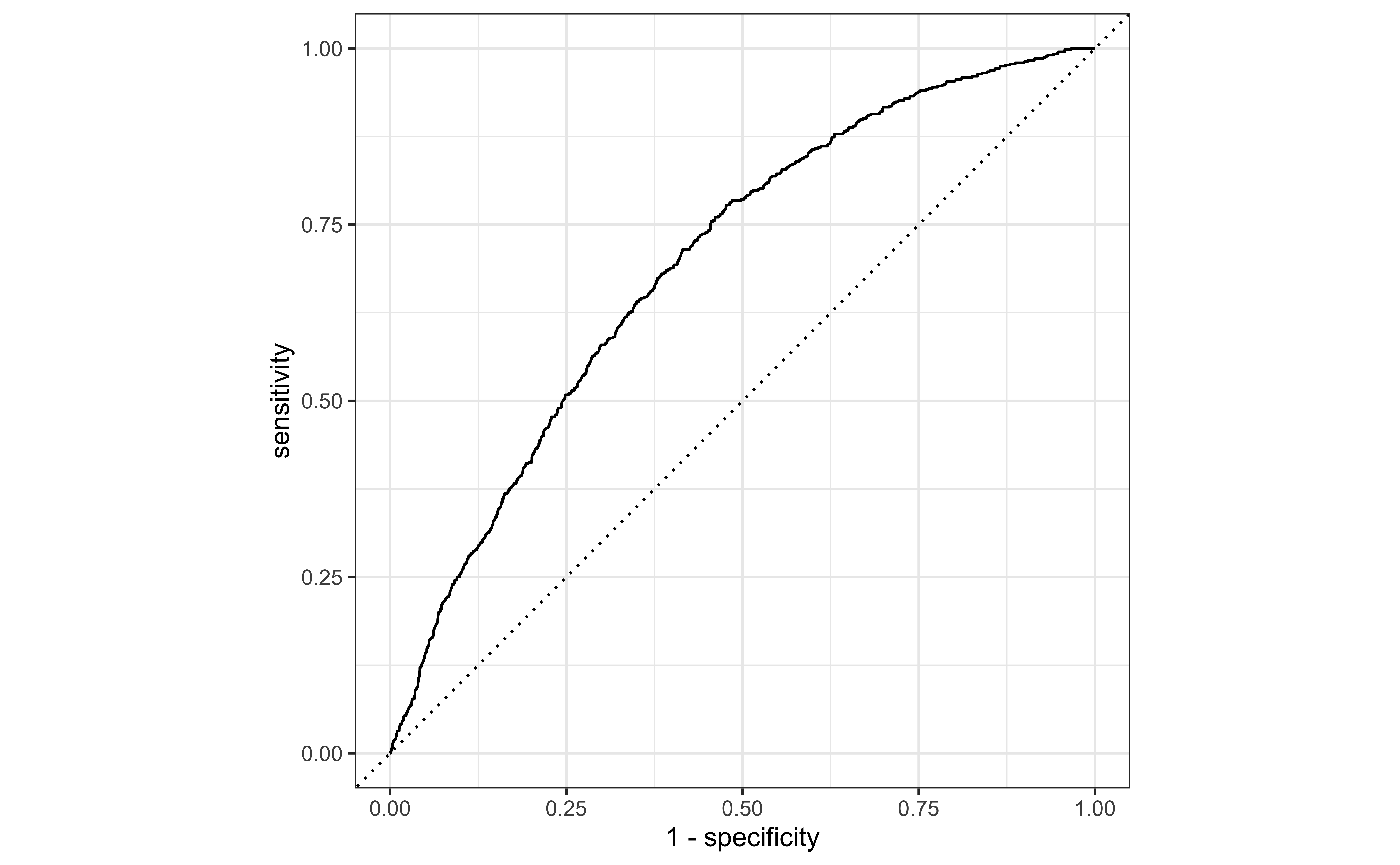
ROC Curve
So far the model assessment has depended on the model and selected threshold. The receiver operating characteristic (ROC) curve allows us to assess the model performance across a range of thresholds.
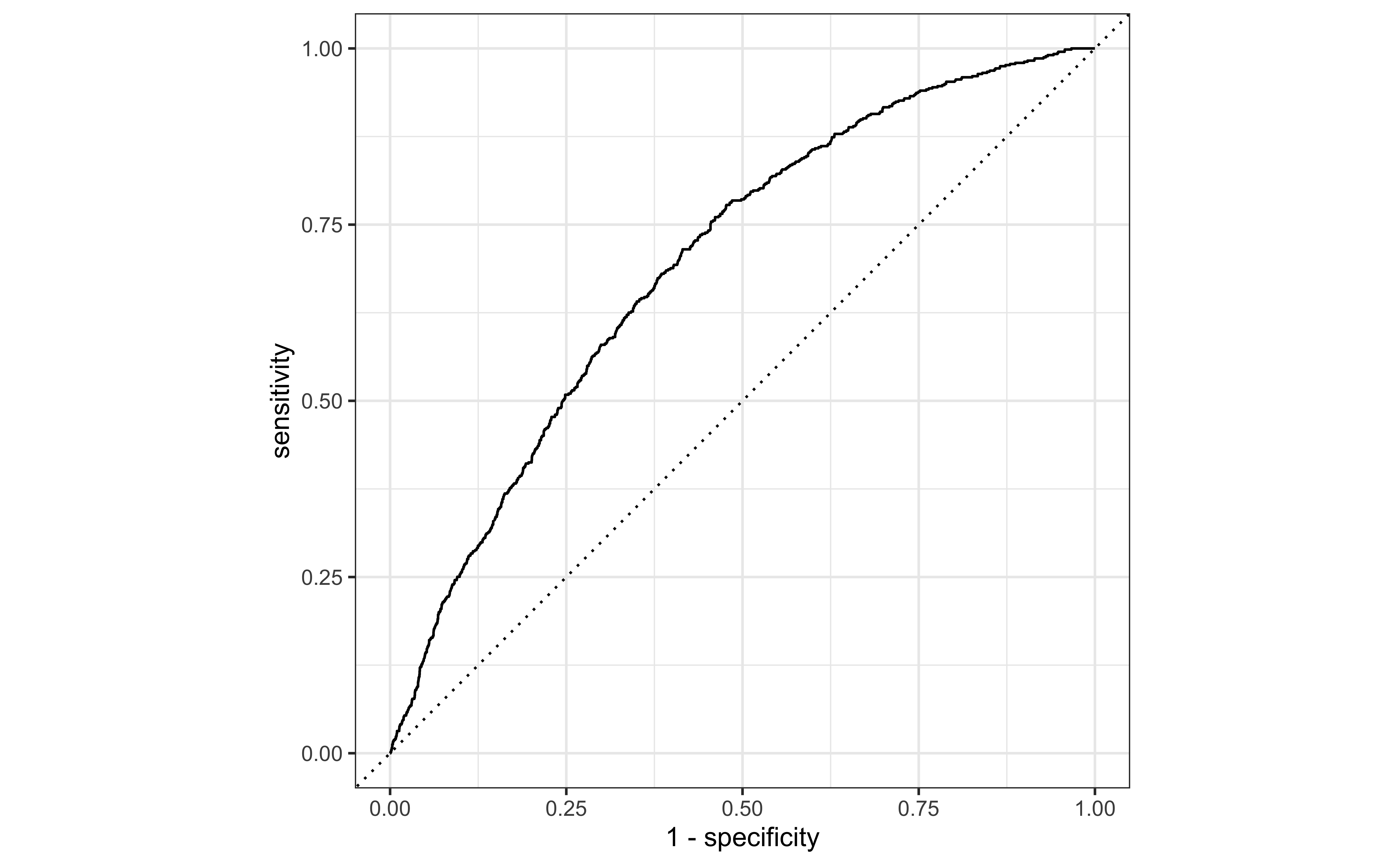
x-axis: 1 - Specificity (False positive rate)
y-axis: Sensitivity (True positive rate)
Which corner of the plot indicates the best model performance?
ROC curve
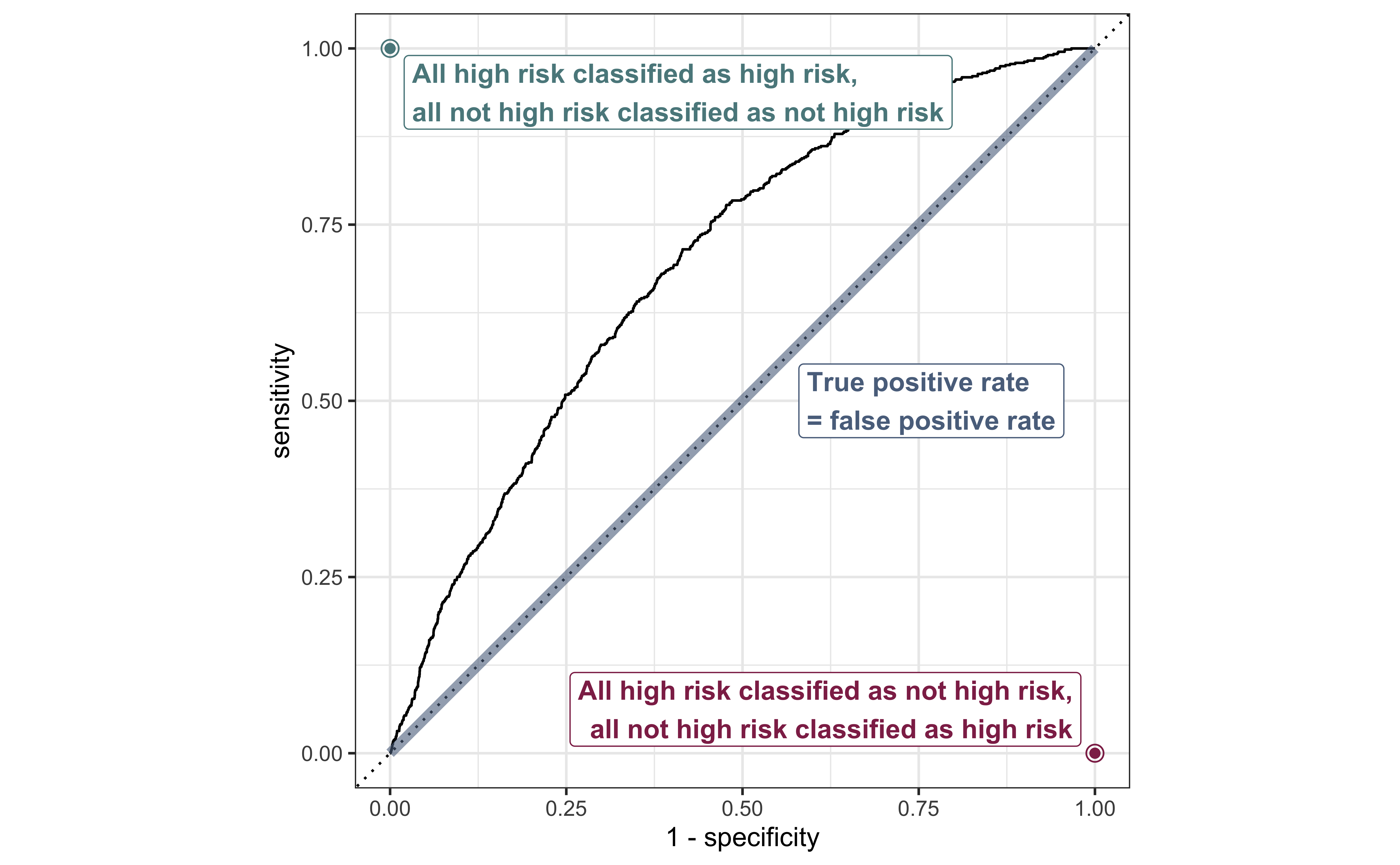
ROC curve in R
Randomly selected observations from roc_data
# A tibble: 20 × 3
.threshold specificity sensitivity
<dbl> <dbl> <dbl>
1 0.0778 0.268 0.929
2 0.119 0.505 0.784
3 0.0990 0.406 0.852
4 0.0664 0.185 0.959
5 0.354 0.974 0.0614
6 0.102 0.422 0.839
7 0.144 0.610 0.682
8 0.225 0.815 0.394
9 0.135 0.577 0.715
10 0.0826 0.302 0.910
11 0.283 0.922 0.217
12 0.136 0.581 0.715
13 0.0659 0.181 0.959
14 0.298 0.938 0.175
15 0.0554 0.110 0.980
16 0.161 0.670 0.614
17 0.136 0.584 0.715
18 0.0511 0.0861 0.983
19 0.111 0.466 0.808
20 0.0612 0.145 0.969