# load packages
library(tidyverse) # for data wrangling
library(tidymodels) # for modeling
library(knitr) # for formatting tables
# set default theme and larger font size for ggplot2
ggplot2::theme_set(ggplot2::theme_bw(base_size = 16))
# set default figure parameters for knitr
knitr::opts_chunk$set(
fig.width = 8,
fig.asp = 0.618,
fig.retina = 3,
dpi = 300,
out.width = "80%"
)Simple Linear Regression
January 15, 2026
Movie scores
- Data behind the FiveThirtyEight story Be Suspicious Of Online Movie Ratings, Especially Fandango’s
- Data originally from the
fandangodata frame in fivethirtyeight package. Available inmovie-scores.csv - Contains every film released in 2014 and 2015 that has at least 30 fan reviews on Fandango, an IMDb score, Rotten Tomatoes critic and user ratings, and Metacritic critic and user scores




Movie scores data
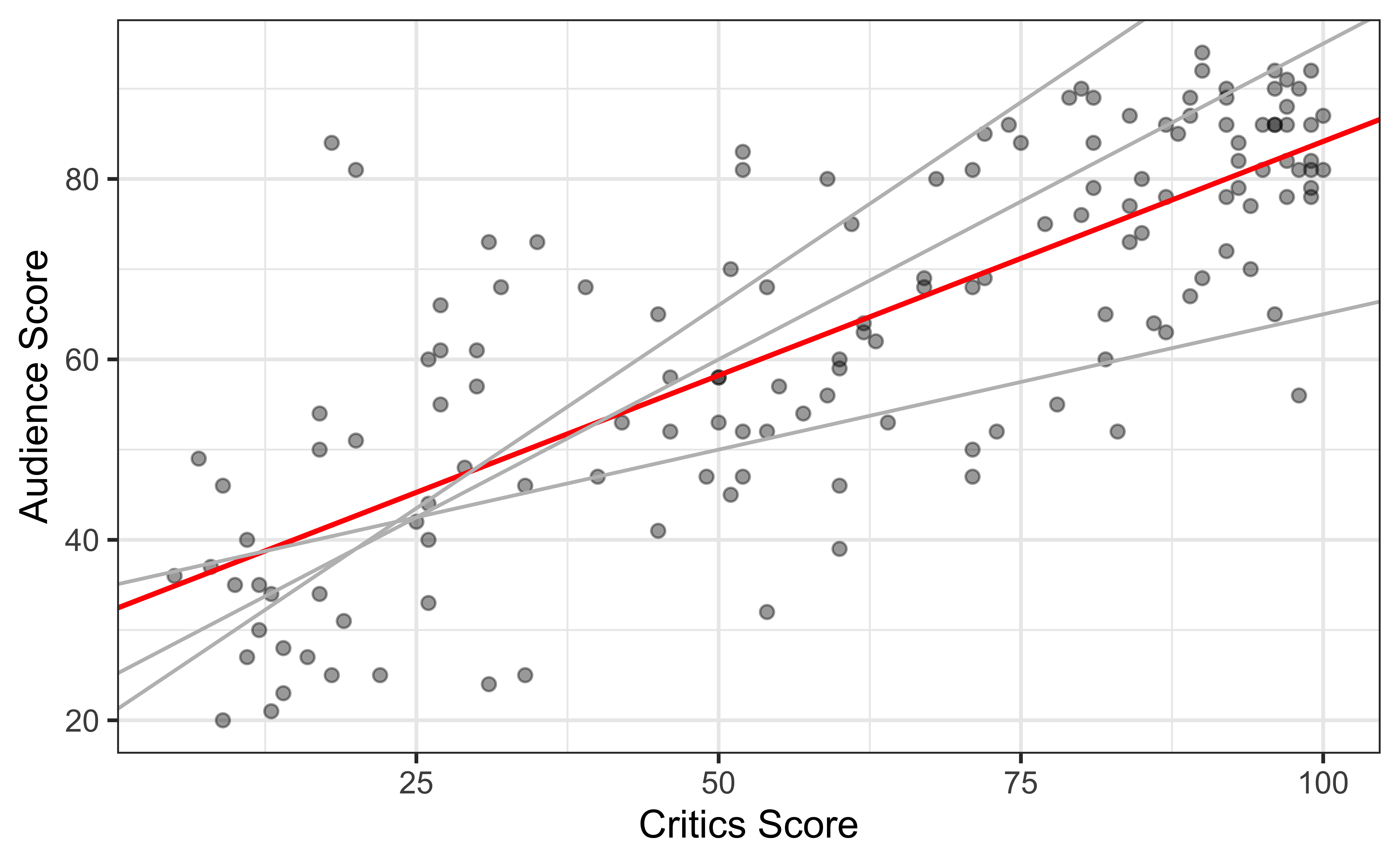
The data set contains the “Tomatometer” score (critics_score) and audience score (audience_score) for 146 movies rated on rottentomatoes.com.
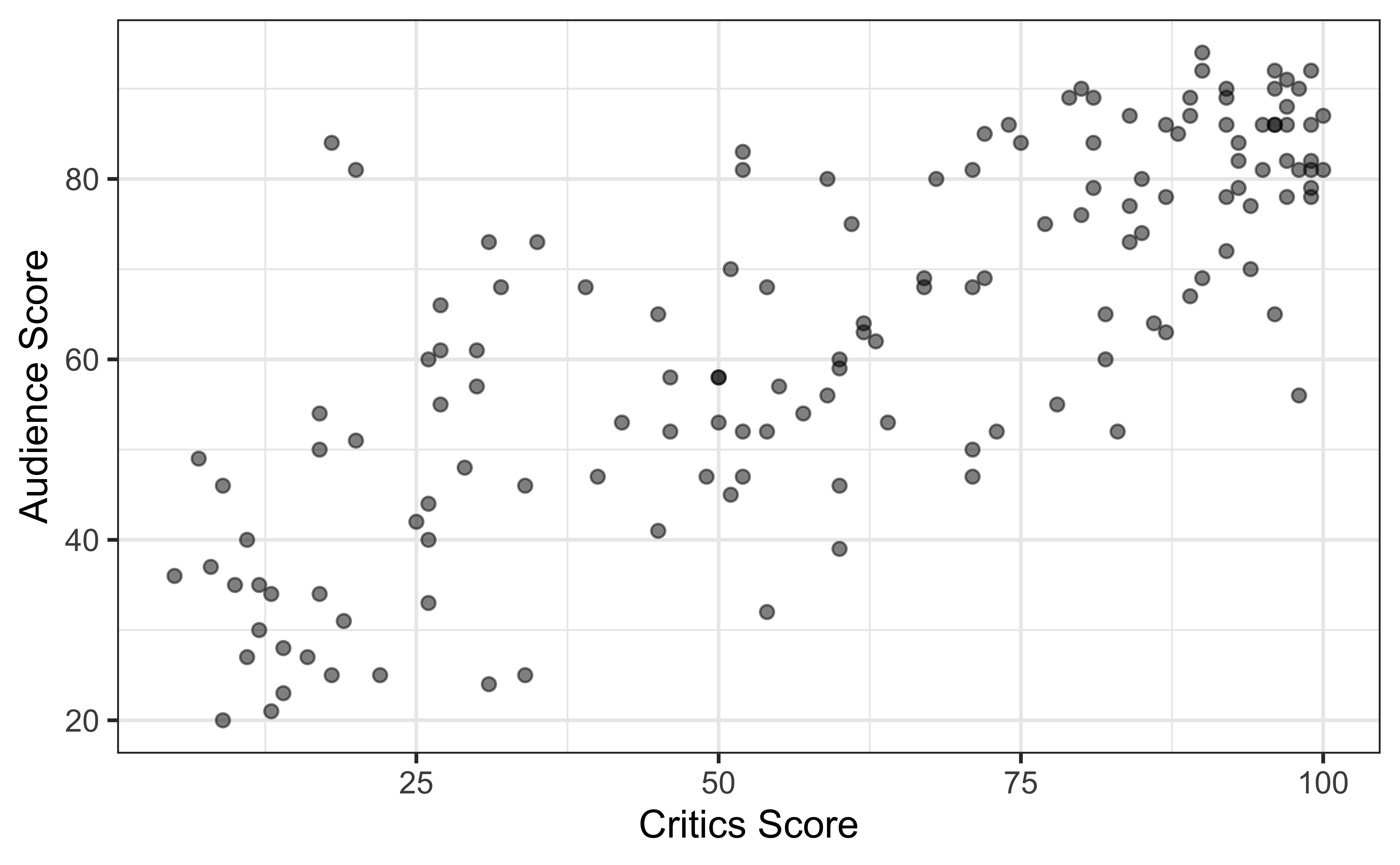
Movie ratings data
Goal: Fit a line to describe the relationship between the critics score and audience score.
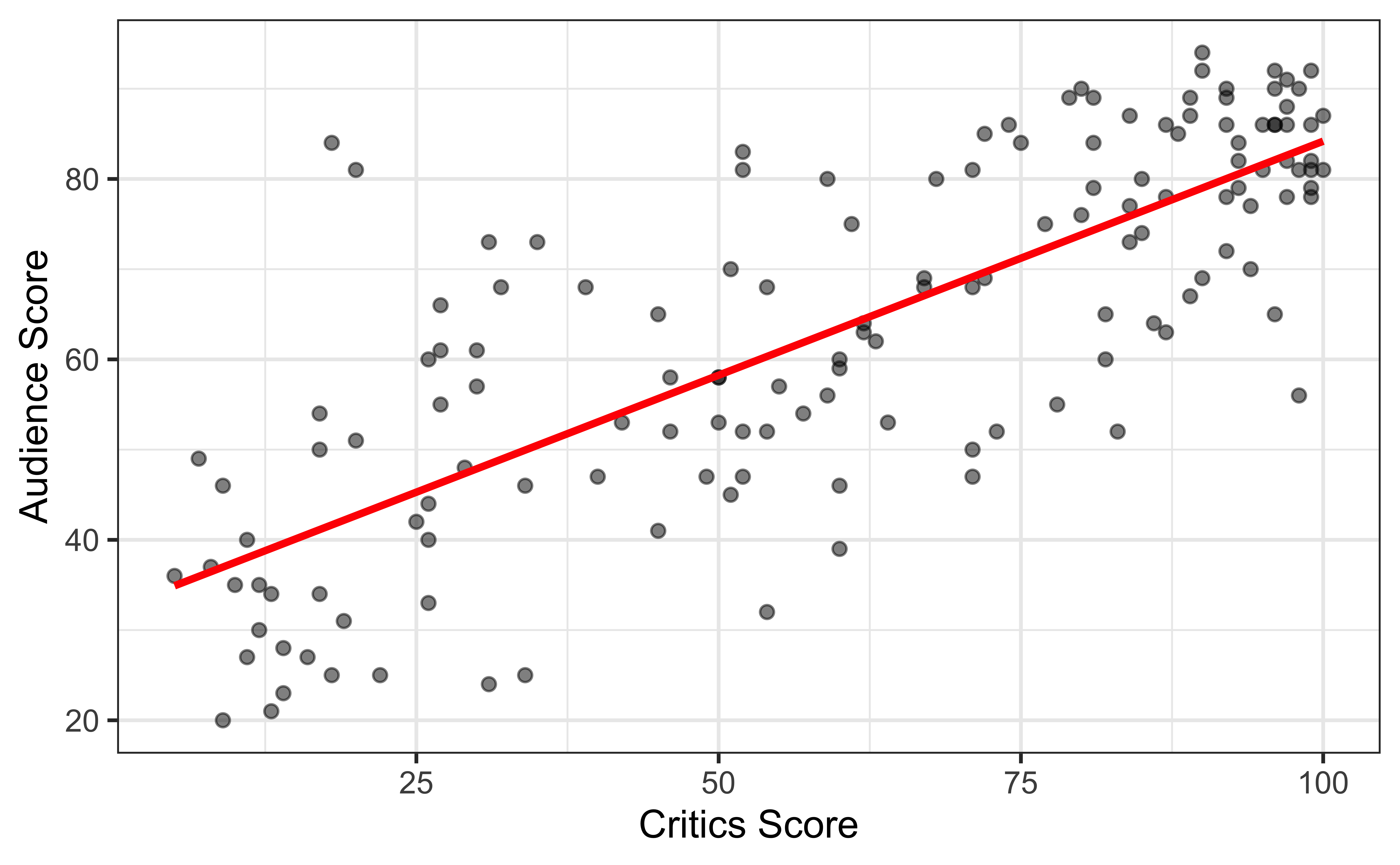
Terminology
Response, Y: variable describing the outcome of interest
Predictor, X: variable we use to help understand the variability in the response
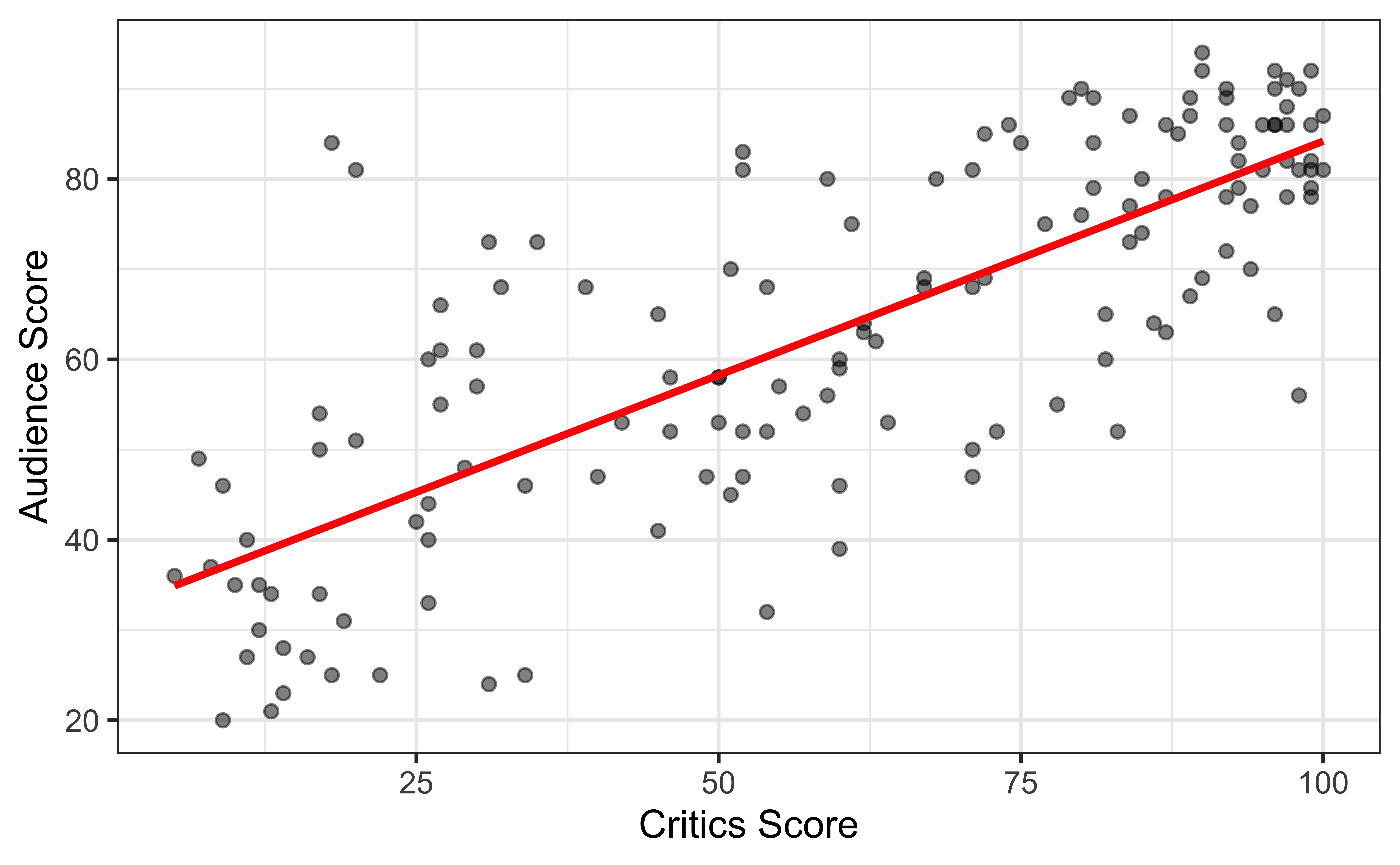
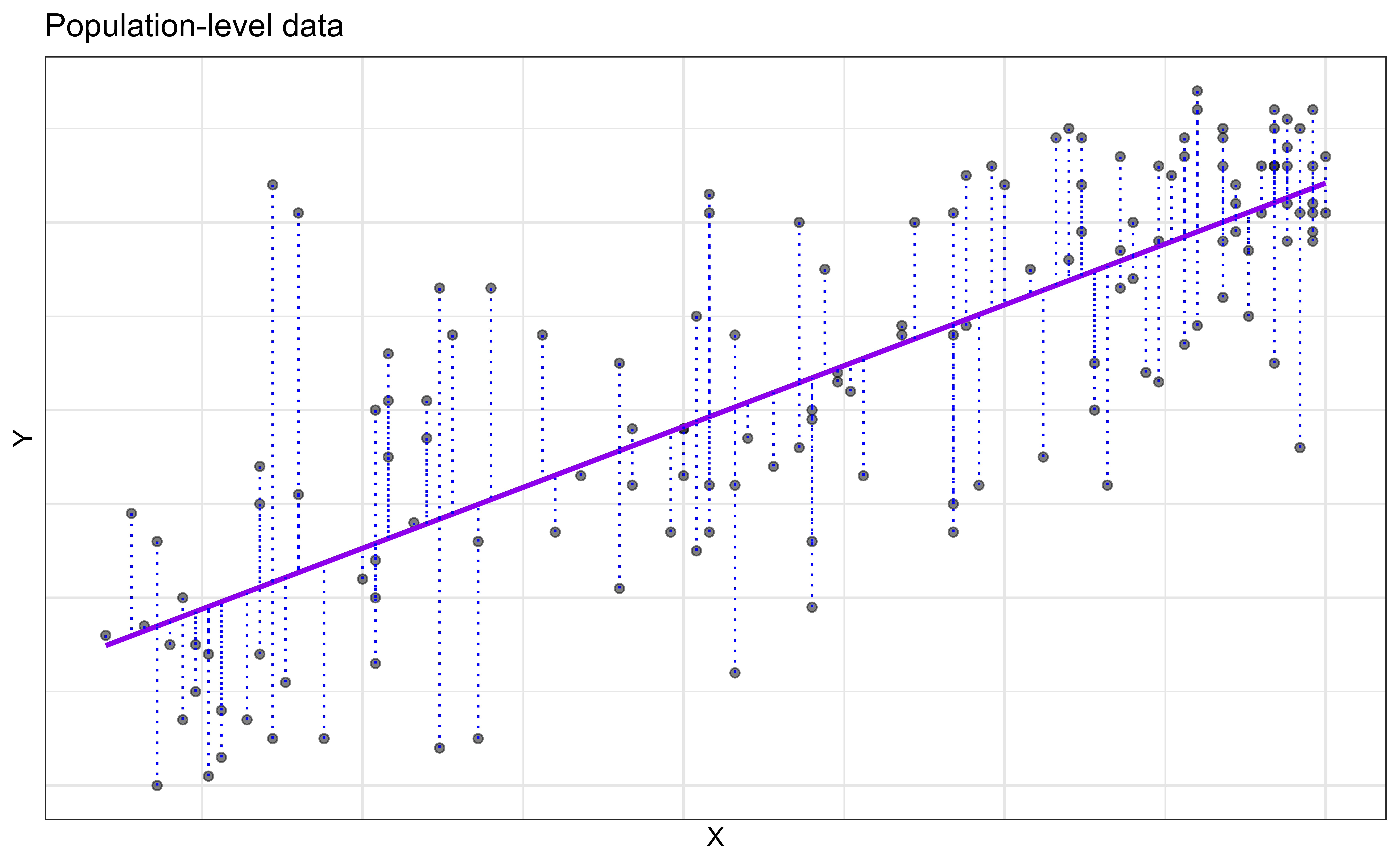
Regression model
\[\begin{aligned} Y &= {\color{purple} \textbf{Model}} + \textbf{Error} \\[8pt]
&= {\color{purple} \mathbf{f(X)}} + \epsilon \\[8pt]
&= {\color{purple} \mathbf{E(Y|X)}} + \epsilon \\ \end{aligned}\]
\(E(Y|X) = \mu_{Y|X}\) is the mean value of \(Y\) given a particular value of \(X\).
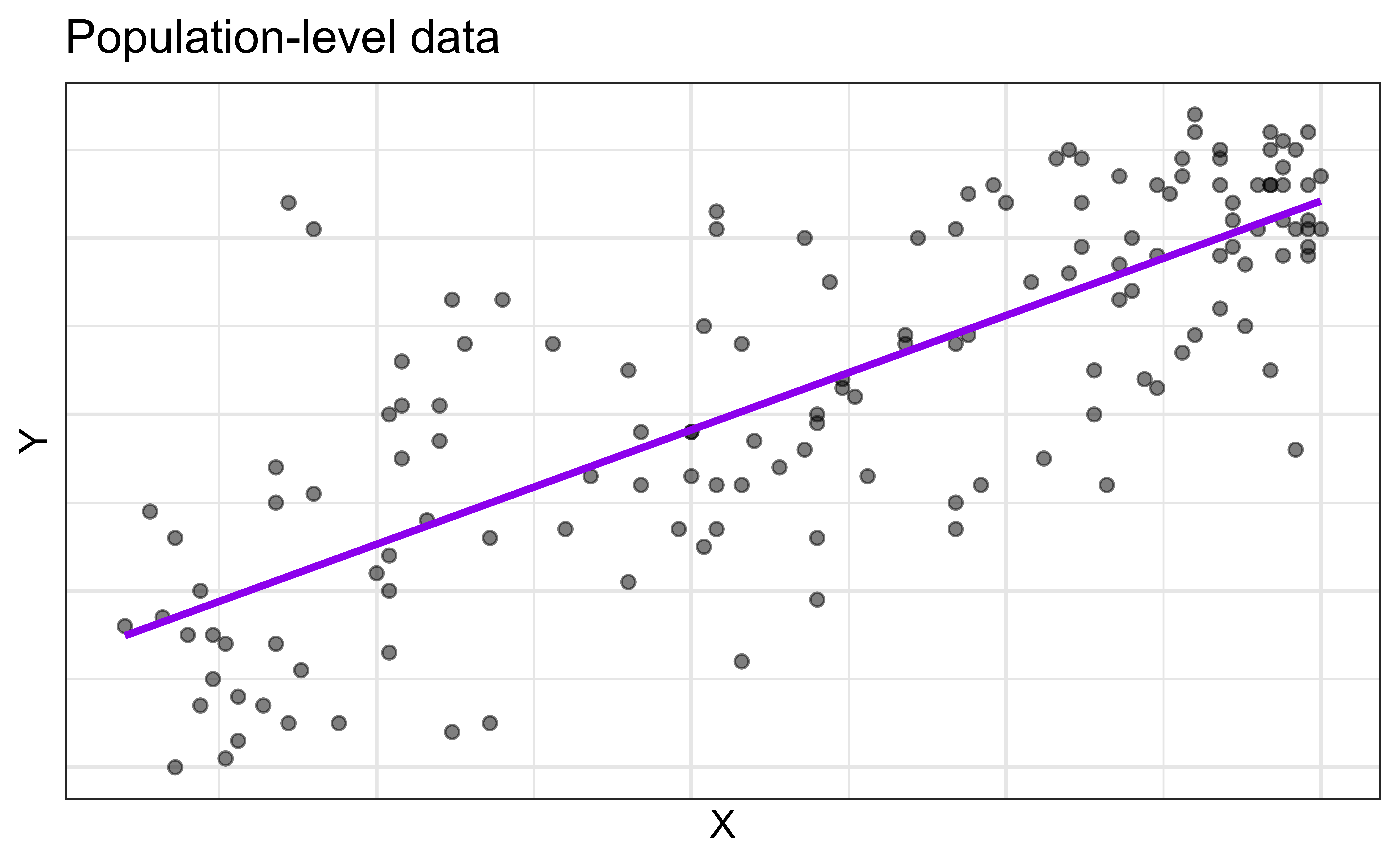
Regression model
\[ \begin{aligned} Y &= \color{purple}{\textbf{Model}} + \color{blue}{\textbf{Error}} \\[8pt] &= \color{purple}{\mathbf{f(X)}} + \color{blue}{\boldsymbol{\epsilon}} \\[8pt] &= \color{purple}{\mathbf{E(Y|X)}} + \color{blue}{\boldsymbol{\epsilon}} \\ \end{aligned} \]
Computing estimates \(\hat{\beta}_1\) and \(\hat{\beta}_0\)
Residuals
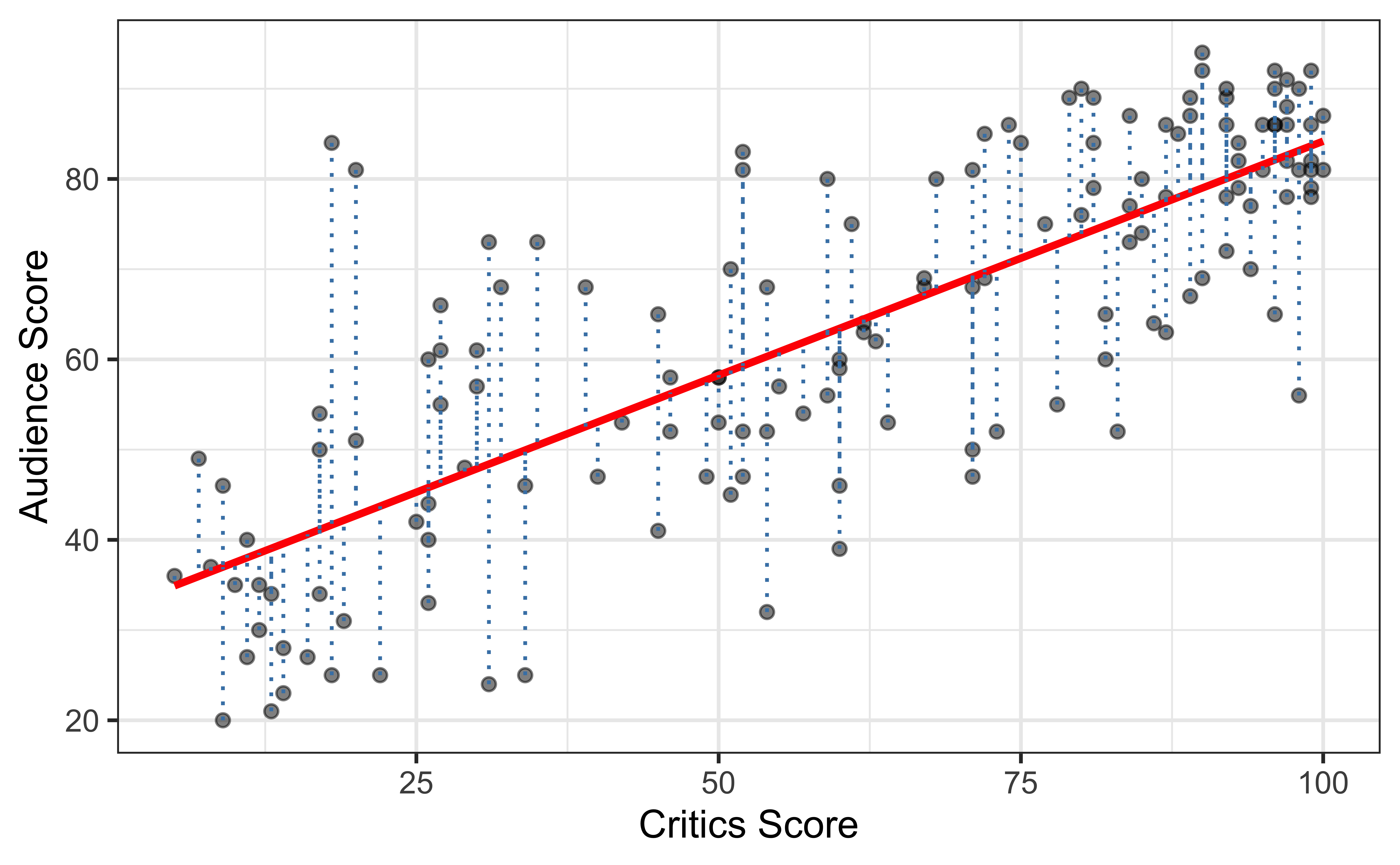
\[\text{residual} = \text{observed} - \text{predicted} = y_i - \hat{y}_i\]